Basic Usage¶
This tutorial will show you how to import metadata from the Dataverse software’s own JSON format, create pyDataverse objects from it (Dataverse collection, Dataset and Datafile), upload it via the API, and clean up at the end.
In addition to this tutorial, you can find more advanced examples at User Guide - Advanced Usage and background information at User Guide - Use-Cases.
Prepare¶
Requirements
- pyDataverse installed (see Installation)
Basic Information
- Follow the order of code execution
- Dataverse Docker 4.18.1 used
- pyDataverse 0.3.0 used
- API responses may vary by each request and Dataverse installation!
Warning
Do not execute the example code on a Dataverse production instance, unless 100% sure!
Additional Resources
- Data from
tests/data/user-guide/used (GitHub repo)
Connect to Native API¶
First, create a NativeApi instance. You will use it
later for data creation. Replace the following variables with your own installation’s data
before you execute the lines:
- BASE_URL: Base URL of your Dataverse installation, without trailing slash (e. g.
https://data.aussda.at)) - API_TOKEN: API token of a Dataverse installation user with proper permissions to create a Dataverse collection, create a Dataset, and upload Datafiles
>>> from pyDataverse.api import NativeApi
>>> api = NativeApi(BASE_URL, API_TOKEN)
Check with get_info_version(),
if the API connection works and to retrieve the version of your Dataverse instance:
>>> resp = api.get_info_version()
>>> resp.json()
{'status': 'OK', 'data': {'version': '4.15.1', 'build': '1377-701b56b'}}
>>> resp.status_code
200
All API requests return a requests.Response object, which
can then be used (e. g. json()).
Create Dataverse Collection¶
The top-level data-type in the Dataverse software is called a Dataverse collection, so we will start with that. Take a look at the figure below to better understand the relationship between a Dataverse collection, a dataset, and a datafile.
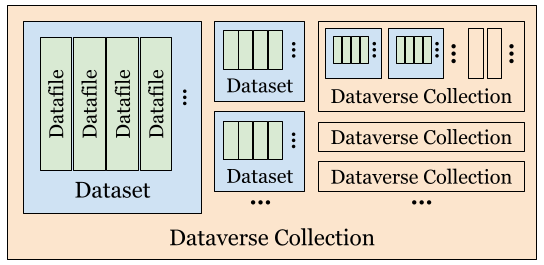
A dataverse collection (also known as a Dataverse) acts as a container for your Datasets.
It can also store other collections (Dataverses).
You could create your own Dataverse collections, but it is not a requirement.
A Dataset is a container for Datafiles, such as data, documentation, code, metadata, etc.
You need to create a Dataset to deposit your files. All Datasets are uniquely identified with a DOI at Dataverse.
For more detailed explanations, check out the Dataverse User Guide.
Going back to the example, first, instantiate a Dataverse
object and import the metadata from the Dataverse Software’s own JSON format with
from_json():
>>> from pyDataverse.models import Dataverse
>>> from pyDataverse.utils import read_file
>>> dv = Dataverse()
>>> dv_filename = "dataverse.json"
>>> dv.from_json(read_file(dv_filename))
With get() you can
have a look at all the data of the object:
>>> dv.get()
{'alias': 'pyDataverse_user-guide', 'name': 'pyDataverse - User Guide', 'dataverseContacts': [{'contactEmail': 'info@aussda.at'}]}
>>> type(dv.get())
<class 'dict'>
To see only the metadata necessary for the Dataverse API upload, use
json(), which defaults
to the needed format for the Dataverse API upload
(equivalent to json(data_format="dataverse_upload")):
>>> dv.json()
'{\n "alias": "pyDataverse_user-guide",\n "dataverseContacts": [\n {\n "contactEmail": "info@aussda.at"\n }\n ],\n "name": "pyDataverse - User Guide"\n}'
>>> type(dv.json())
<class 'str'>
Then use create_dataverse() to
upload the Dataverse metadata to your Dataverse installation via its Native API and
create an unpublished Dataverse collection draft. For this, you have to pass a) the parent
Dataverse collection alias to which the new Dataverse collection is attached and b) the metadata in the Dataverse Software’s
own JSON format (json()):
>>> resp = api.create_dataverse(":root", dv.json())
Dataverse pyDataverse_user-guide created.
Last, we publish the Dataverse collection draft with
publish_dataverse():
>>> resp = api.publish_dataverse("pyDataverse_user-guide")
Dataverse pyDataverse_user-guide published.
To have a look at the results of our work, you can check the created Dataverse collection
on the frontend, or use pyDataverse to retrieve the Dataverse collection with
get_dataverse():
>>> resp = api.get_dataverse("pyDataverse_user-guide")
>>> resp.json()
{'status': 'OK', 'data': {'id': 441, 'alias': 'pyDataverse_user-guide', 'name': 'pyDataverse - User Guide', 'dataverseContacts': [{'displayOrder': 0, 'contactEmail': 'info@aussda.at'}], 'permissionRoot': True, 'dataverseType': 'UNCATEGORIZED', 'ownerId': 1, 'creationDate': '2021-01-13T20:47:43Z'}}
This is it, our first Dataverse collection created with the help of pyDataverse! Now let’s move on and apply what we’ve learned to Datasets and Datafiles.
Create Dataset¶
Again, start by creating an empty pyDataverse object, this time a
Dataset:
>>> from pyDataverse.models import Dataset
>>> ds = Dataset()
The function names often are the same for each data-type. So again, we can use
from_json() to import
the metadata from the JSON file, but this time it feeds into a Dataset:
>>> ds_filename = "dataset.json"
>>> ds.from_json(read_file(ds_filename))
You can also use get()
to output all data:
>>> ds.get()
{'citation_displayName': 'Citation Metadata', 'title': 'Youth in Austria 2005', 'author': [{'authorName': 'LastAuthor1, FirstAuthor1', 'authorAffiliation': 'AuthorAffiliation1'}], 'datasetContact': [{'datasetContactEmail': 'ContactEmail1@mailinator.com', 'datasetContactName': 'LastContact1, FirstContact1'}], 'dsDescription': [{'dsDescriptionValue': 'DescriptionText'}], 'subject': ['Medicine, Health and Life Sciences']}
Now, as the metadata is imported, we don’t know if the data is valid and can be used
to create a Dataset. Maybe some attributes are missing or misnamed, or a
mistake during import happened. pyDataverse offers a convenient function
to test this out with
validate_json(), so
you can move on with confidence:
>>> ds.validate_json()
True
Adding or updating data manually is easy. With
set()
you can pass any attribute you want as a collection of key-value
pairs in a dict:
>>> ds.get()["title"]
Youth in Austria 2005
>>> ds.set({"title": "Youth from Austria 2005"})
>>> ds.get()["title"]
Youth from Austria 2005
To upload the Dataset, use
create_dataset().
You’ll pass the Dataverse collection where the Dataset should be attached
and include the metadata as a JSON string
(json()):
>>> resp = api.create_dataset("pyDataverse_user-guide", ds.json())
Dataset with pid 'doi:10.5072/FK2/EO7BNB' created.
>>> resp.json()
{'status': 'OK', 'data': {'id': 442, 'persistentId': 'doi:10.5072/FK2/EO7BNB'}}
Save the created PID (short for Persistent Identifier, which in
our case is the DOI) in a dict:
>>> ds_pid = resp.json()["data"]["persistentId"]
Private Dataset URL’s can also be created. Use
create_dataset_private_url()
to get the URL and the private token:
>>> resp = api.create_dataset_private_url(ds_pid)
Dataset private URL created: http://data.aussda.at/privateurl.xhtml?token={PRIVATE_TOKEN}
>>> resp.json()
{'status': 'OK', 'data': {'token': '{PRIVATE_TOKEN}', 'link': 'http://data.aussda.at/privateurl.xhtml?token={PRIVATE_TOKEN}', 'roleAssignment': {'id': 174, 'assignee': '#442', 'roleId': 8, '_roleAlias': 'member', 'privateUrlToken': '{PRIVATE_TOKEN}', 'definitionPointId': 442}}}
Finally, to make the Dataset public, publish the draft with
publish_dataset().
Set release_type="major" (defaults to minor), to create version 1.0:
>>> resp = api.publish_dataset(ds_pid, release_type="major")
Dataset doi:10.5072/FK2/EO7BNB published
Upload Datafile¶
After all the preparations, it’s now time to upload a
Datafile and attach it to the Dataset:
>>> from pyDataverse.models import Datafile
>>> df = Datafile()
Again, import your metadata with from_json().
Then, set your PID and filename manually (set()),
as they are required as metadata for the upload and are created during the
import process:
>>> df_filename = "datafile.txt"
>>> df.set({"pid": ds_pid, "filename": df_filename})
>>> df.get()
{'pid': 'doi:10.5072/FK2/EO7BNB', 'filename': 'datafile.txt'}
Upload the Datafile with
upload_datafile().
Pass the PID, the Datafile filename and the Datafile metadata:
>>> resp = api.upload_datafile(ds_pid, df_filename, df.json())
>>> resp.json()
{'status': 'OK', 'data': {'files': [{'description': '', 'label': 'datafile.txt', 'restricted': False, 'version': 1, 'datasetVersionId': 101, 'dataFile': {'id': 443, 'persistentId': '', 'pidURL': '', 'filename': 'datafile.txt', 'contentType': 'text/plain', 'filesize': 7, 'description': '', 'storageIdentifier': '176fd85f46f-cf06cf243502', 'rootDataFileId': -1, 'md5': '8b8db3dfa426f6bdb1798d578f5239ae', 'checksum': {'type': 'MD5', 'value': '8b8db3dfa426f6bdb1798d578f5239ae'}, 'creationDate': '2021-01-13'}}]}}
By uploading the Datafile, the attached Dataset gets an update.
This means that a new unpublished Dataset version is created as a draft
and the change is not yet publicly available. To make it available
through creating a new Dataset version, publish the Dataset with
publish_dataset().
Again, set the release_type="major" to create version 2.0, as a file change
always leads to a major version change:
>>> resp = api.publish_dataset(ds_pid, release_type="major")
Dataset doi:10.5072/FK2/EO7BNB published
Download and save a dataset to disk¶
You may want to download and explore an existing dataset from Dataverse. The following code snippet will show how to retrieve and save a dataset to your machine.
Note that if the dataset is public, you don’t need to have an API_TOKEN. Furthermore, you don’t even need to have a Dataverse account to use this functionality. The code would therefore look as follows:
>>> from pyDataverse.api import NativeApi, DataAccessApi
>>> from pyDataverse.models import Dataverse
>>> base_url = 'https://dataverse.harvard.edu/'
>>> api = NativeApi(base_url)
>>> data_api = DataAccessApi(base_url)
However, you need to know the DOI of the dataset that you want to download. In this example, we use doi:10.7910/DVN/KBHLOD, which is hosted on Harvard’s Dataverse instance that we specified as base_url. The code looks as follows:
>>> DOI = "doi:10.7910/DVN/KBHLOD"
>>> dataset = api.get_dataset(DOI)
As previously mentioned, every dataset comprises of datafiles, therefore, we need to get the list of datafiles by ID and save them on disk. That is done in the following code snippet:
>>> files_list = dataset.json()['data']['latestVersion']['files']
>>> for file in files_list:
>>> filename = file["dataFile"]["filename"]
>>> file_id = file["dataFile"]["id"]
>>> print("File name {}, id {}".format(filename, file_id))
>>> response = data_api.get_datafile(file_id)
>>> with open(filename, "wb") as f:
>>> f.write(response.content)
File name cat.jpg, id 2456195
Please note that in this example, the dataset will be saved in the execution directory. You could change that by adding a desired path in the open() function above.
Retrieve all created data as a Dataverse tree¶
PyDataverse offers a convenient way to retrieve all children-data from a specific Dataverse collection or Dataset down to the Datafile level (Dataverse collections, Datasets and Datafiles).
Simply pass the identifier of the parent (e. g. Dataverse collection alias or Dataset
PID) and the list of the children data-types that should be collected
(dataverses, datasets, datafiles) to
get_children():
>>> tree = api.get_children("pyDataverse_user-guide", children_types= ["datasets", "datafiles"])
>>> tree
[{'dataset_id': 442, 'pid': 'doi:10.5072/FK2/EO7BNB', 'type': 'dataset', 'children': [{'datafile_id': 443, 'filename': 'datafile.txt', 'label': 'datafile.txt', 'pid': '', 'type': 'datafile'}]}]
In our case, we don’t use dataverses as children data-type, as there
is none inside the created Dataverse collection.
For further use of the tree, have a look at
dataverse_tree_walker()
and save_tree_data().
Clean up and remove all created data¶
As we have created a Dataverse collection, created a Dataset, and uploaded a Datafile, we now will remove all of it in order to clean up what we did so far.
The Dataset has been published in the step above, so we have to destroy it with
destroy_dataset().
To remove a non-published Dataset,
delete_dataset()
must be used instead.
Note: When you delete a Dataset, it automatically deletes all attached Datafile(s):
>>> resp = api.destroy_dataset(ds_pid)
Dataset {'status': 'OK', 'data': {'message': 'Dataset :persistentId destroyed'}} destroyed
When you want to retrieve the Dataset now with
get_dataset(), pyDataverse throws an
OperationFailedError
exception, which is the expected behaviour, as the Dataset was deleted:
>>> resp = api.get_dataset(ds_pid)
pyDataverse.exceptions.OperationFailedError: ERROR: GET HTTP 404 - http://data.aussda.at/api/v1/datasets/:persistentId/?persistentId=doi:10.5072/FK2/EO7BNB. MSG: {"status":"ERROR","message":"Dataset with Persistent ID doi:10.5072/FK2/EO7BNB not found."}
After removing all Datasets and/or Dataverse collections in it, delete the parent Dataverse collection
(delete_dataverse()).
Note: It is not possible to delete a Dataverse collection with any data (Dataverse collection or Dataset) attached to it.
>>> resp = api.delete_dataverse("pyDataverse_user-guide")
Dataverse pyDataverse_user-guide deleted.
Now the Dataverse instance is as it was once before we started.
The Basic Usage tutorial is now finished, but maybe you want to have a look at more advanced examples at User Guide - Advanced Usage and at User Guide - Use-Cases for more information.
